How to use Git

Git is a free and open-source distributed version control system designed for tracking changes in source code during software development. It's a system that records changes to the files over time and we can recall specific versions of those files at any given time.
Installing Git
Most of the Linux-based OS and macOS come with Git pre-installed. You can check that by using git --version in the terminal. However, if Git is not pre-installed, there are two ways to do this:
Go to Git Official Website and download the package according to your OS.
For Windows, you can alternatively download cmder. This is a nice alternative to Terminal that is missing in Windows and it comes with Git installed.
Again, to check if the Git is installed correctly, you can run git --version in the Terminal.
Before we move forward we will set up a username and an email. This is so that the Git knows who is making the changes. First, we will set the username in the global capacity by running the command
git config --global user.name <your_username>
Now we will set our email by using
git config --global user.email <your_email>
You can check your set username by using git config user.name. Similarly, you can also check your email.
Creating a Git repository
We will first cd to the directory that contains our project files. To make the current directory a git repository run the command
git init
That's it. We have initialised a Git repository. However, we haven't made any commit yet. This was just the initialisation process.
Staging files
Before we can make commit we have to stage the files. Staging is an extra step before commit. If we have multiple files that are to be saved in two different commits, staging comes handy.
To view the files that have been changed since the previous commit, run the command git status. All the files that have been changed since the last commit and have not been staged will be shown in red colour.
To stage files, we will use git add <filename>. In my case, I'll use git add index.html
If we have multiple files and we want to stage them all, so instead to adding individual files we can use git add . and all the files will be added to the staging area.
All the staged files will be shown green in colour.
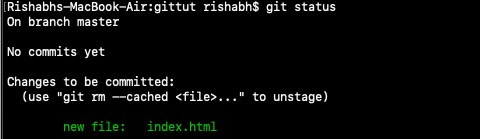
If we have to unstage any file, we can use the command git rm --cached <filename> to remove that file from the staging area.
Making Commits
Now that we have all the required files in the staging area, we are ready to make our first commit. To do so, simply run the command
git commit -m "any commit message"
The -m flag is used to pass a commit message that will be shown when we look at the commit history. Once we run the command we will get a few details of our commit.

I have made my first commit. The details which we get are:
master: name of the branch in which the commit is made.81fda69: first seven characters of the long commit id. Usually, this small id is enough to get all our work done.First commit: the commit message that we passed while making the commit.1 file changed, 3 insertions(+): the number of files in which changes were made, and the total number of lines that were inserted or deleted.
To view all the commits that we have made, run the command git log. This will show the commit history in a detailed manner. To view the commit history in one-line format, run git commit --oneline. You can see the commit id along with their commit message in one-line format.

Output for git commit --oneline
Undoing Changes
If we ever make a commit by mistake, just look at a previous commit, or have to permanently go back to a previous commit, Git provides three ways of doing that:
Checkout
Revert
Reset
checkout
Suppose we have to go back to a previous commit to check the files at that particular point without changing anything in the process. To do so, run the command
git checkout <commit_id>
When we run this command, all the files in the repository will change to the way they were at that commit. However, this change is not permanent. When we are finished checking the files, we can come back to the latest commit by running the command
git checkout master
Here master is the branch name in which we are making the changes.
revert
Suppose you realise that you don't need some new features you added in the recent commits and remove the changes that you made in that commit. For that, run the following command:
git revert <commit_id>
Exit the text editor by typing :wq and press enter. You'll see that a new commit is made with message Revert "Previous commit message". This is in essence not deleting any progress we have made, rather it just remove the changes that were made in that particular commit. We can always go back to those commits using checkout option.
reset
This is potentially a dangerous option so use this carefully. Suppose we want to permanently remove some commits or delete them, we will use reset option. To do so we will run:
git reset <commit_id_till_where_the_commits_are_to_deleted>
This will delete all the commits till that point. However you'll notice that no files have been deleted and the contents of the files are unchanged. This is because this option deletes only the commits, but does not effect the files.
In case you want to totally undo the progress and go back to a previous commit with all your files reverted back as they were in that particular commit, use the --hard flag with the reset option.
git reset <commit_id> --hard
This change is permanent and this cannot be undone.
Branches
Suppose you want to add a test feature to your project but not want to make anything permanent until you are completely sure that it is working properly. Or if there are several people in your team and each one of them is working on a separate feature or bug. In such cases we can create multiple branches in our repository and when we are sure, we can merge those branches to the master branch.
To create a new branch simple run
git branch <branch_name>
A new branch will be created. You can view all the branches in the repository by running the command
git branch -a
The branch that has an asterisk on the left is your current working branch. If we create a branch name feature1, we can move to that branch by running the command
git checkout feature1
You will get a message Switched to branch 'feature1'. Now all the commits that you make will be stored in the branch feature1.
If we wish to delete a branch, move to the master branch by using git checkout master and run the command
git branch -d <branch_name>
This will delete the branch only if this branch is merged with the master branch or if there are no new commits made to it. To delete a branch with new commits or if it is not merged with any other branch, run the command
git branch -D <branch_name>
You cannot delete your current branch. Before deleting move to a different branch.
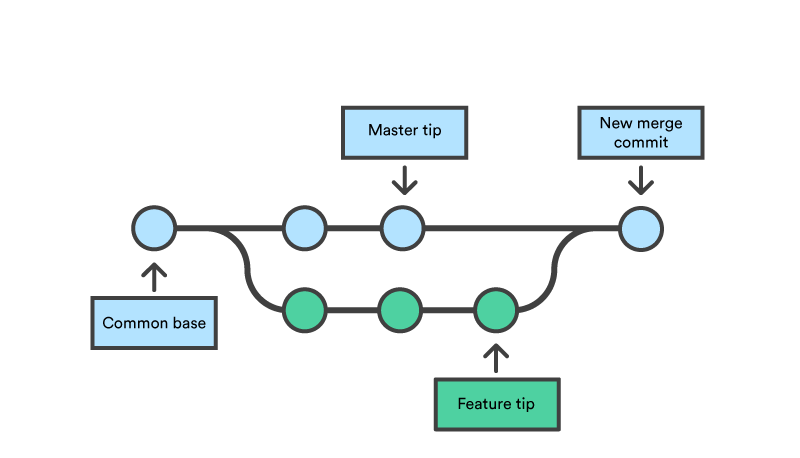
Merging Branches
Finally, when we have a feature ready or we have removed a bug, we may want to merge those changes to our master branch. Now if we wish to merge branch feature1 to our master branch, we will first have to go to the master branch.
git checkout master
Now to merge feature1 to master, run the command
git merge feature1
All the commits in feature1 will be merged in the master branch.
To merge a branch A to branch B, set branch B as your current branch and run the command git merge A
Conflicts in merge
Suppose you are working on feature1 and in the meantime code in the master branch has changed. When you will try to merge feature1 to the master branch you will get an error like

This is a conflict. Now when you open the file with conflict you'll see something like

This shows the lines in the file which are in conflict. Simply remove the lines (and the comment) which are not required and save the file. Now stage the file using git add . and make the commit using git commit. We will not pass the commit message in this. Rather we will get an editor screen like
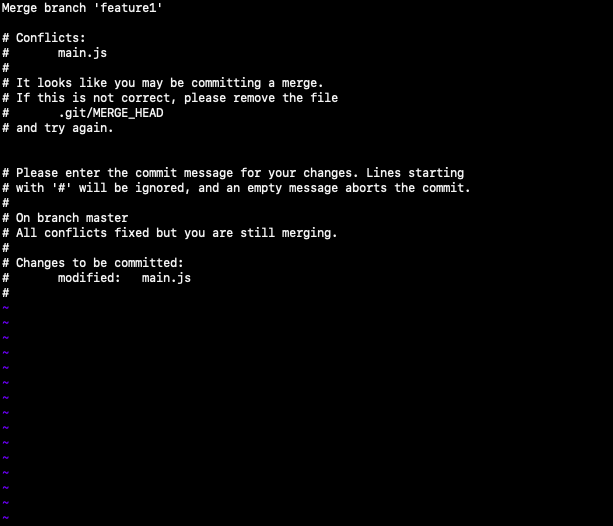
The top line will be the commit message. To keep it unchanged and exit the terminal, type :wq and press enter. A new commit is made with the conflict resolved.
Now if we wish to delete the feature1 branch we can do that by running git branch -d feature1
Using .gitignore
Git tracks all the files and directories that are in the repository. However, there can be certain files or directories that you do not want to be tracked. Some examples can be /node_modules, images' directory or log files.
Simply create a .gitignore file in the root of the repository. The files, or repositories mentioned in the .gitignore will not be tracked by Git.
By default the .gitignore file will be tracked by the Git.
| Pattern | Matches |
| logs/ | logs/ |
logs/access.log
logs/website/access.log |
| logs | This matches both directories and files named logs
/logs/access.log
/apache2/logs |
| *.log | All the files that end with .log in any directory
access.log
logs/website.log |
| **/logs | logs/debug.log
logs/monday/foo.bar
build/logs/debug.log |
| logs/**/debug.log | logs/debug.log
logs/monday/debug.log
logs/monday/pm/debug.log |
| debug[0-9].log | debug0.log
debug5.log
but not
debug10.log |
| debug?.log | debug0.log
debugg.log
but not
debug10.log |
If you wish to ignore the file literally named random[1-2].log use the escape character \ before the square brackets. random\[1-2\].log will ignore the file named random[1-2].log instead of random1.log and random2.log.
These are some of the basic features of Git which will be very helpful in managing project files and versions. Git too has a vast number of features and options. You can check those by running man git.
If you have any comments, suggestions, or feedback let me know in the comments below. Anything and everything is appreciated.

